
Analyzing the Wheel of time with NLP
The Wheel of Time is perhaps the pinnacle of chosen one saves the world fantasy stories. Spanning 14 main books and 1 prequel, 4.4 million words, 704 chapters, and nearly 2800 named characters, it is truly an epic in every sense of the word. Tragically its original author, Robert Jordan, passed away before he could finish the series, but fantasy author Brandon Sanderson (likely the most famous current fantasy author) stepped in at behest of Jordan’s editor and wife, Harriet McDougal, to finish it. Due to its length and the richness of its text with unconventional writing, I thought it would be interesting to investigate with natural language processing (NLP) techniques as part of my fourth project at Metis.
Importing and processing the text
Before I could do anything else, I needed to load the text of the books into Python. I should note that I only used the 14 main series books and not the prequel, partly because the former are more connected, and partly because I had never read the prequel. I looked into a variety of ways of importing the books, and I settled on converting the books to text files using an online tool (not python) and simply reading them in with simple python read statements. I did this because it was much easier than parsing the data from an epub/pdf in python, though I believe some text was slightly messed up in the process. After importing the text, I did some basic cleaning, including removing punctuation, excess white space, etc. I also removed stopwords at this point. Finally, I also singularized all the words using TextBlob’s singularize function. I did so to turn posessives, which looked like plurals after the punctuation removal, into the names of the characters (i.e. Rand’s -> Rands -> Rand). With the text cleaned, I could start investigating the text more.
Writing differences between Jordan and Sanderson
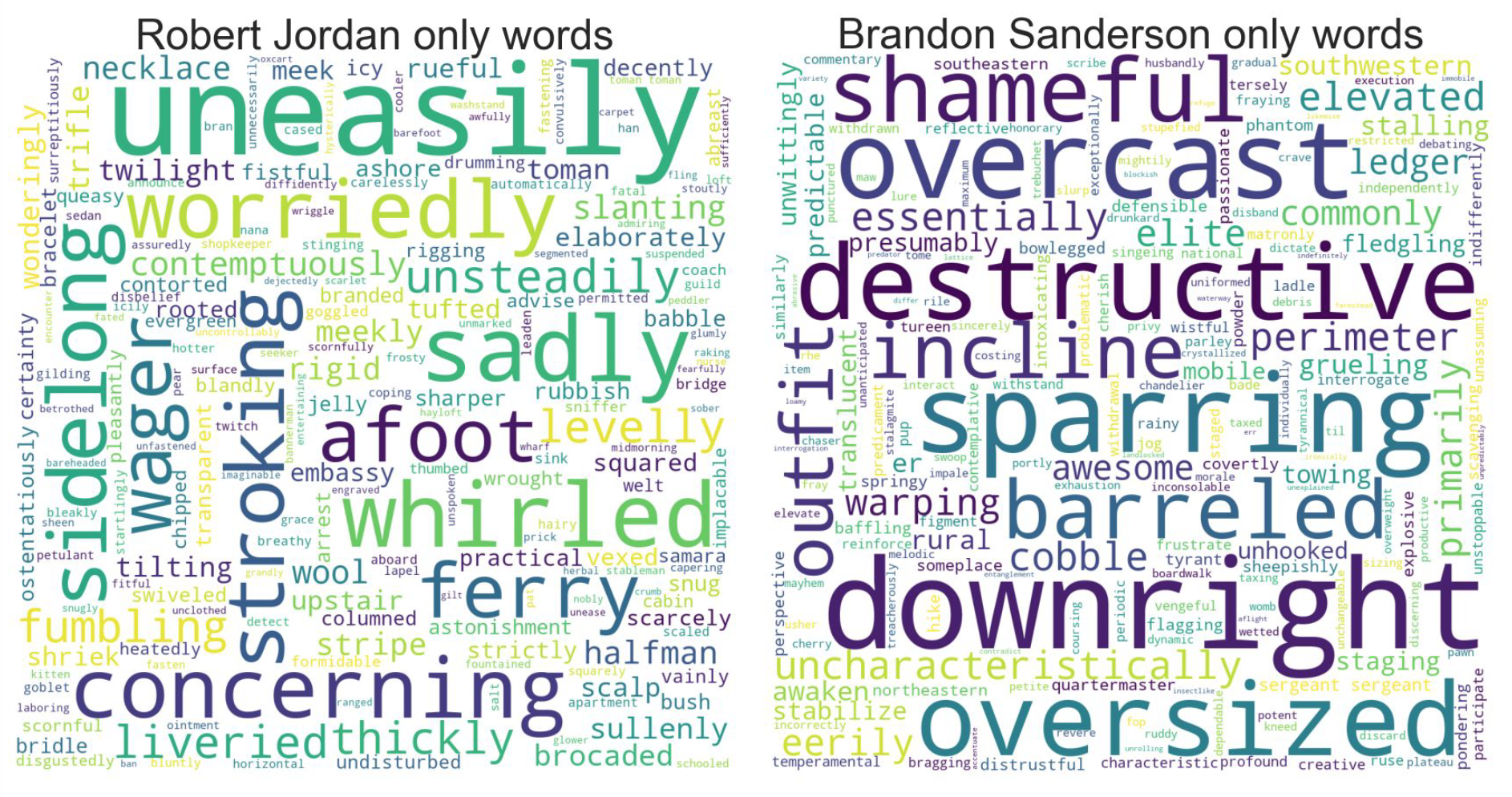
One of the first things that I wanted to investigate were any writing differences between Robert Jordan and Brandon Sanderson. I separated the books into the first 11 (which Jordan wrote exclusively) and the last 3 (written mostly by Sanderson). Then, using NLTK’s part of speech tagger, I looked at the verbs, adverbs, and adjectives that one author used that the other did not. I chose these parts of speech because I believed that these would be the largest differentiators of writing style. I turned the most frequent of these for each author into a wordcloud, which you can see below. What I found largely matched with my expectations: Jordan is known for more flowery and descriptive language, reflected in the large number of prominent adverbs. Sanderson on the other hand uses more straight forward and action-oriented language, which can be seen from words like “destructive” and “barreling”.
Topic Modeling
Writing difference analysis finished, I turned to topic modeling. After trying a variety of methods, I found that sklearn’s TfidfVectorizer and NMF worked best. I included both unigrams and bigrams in the vectorizer as there are many important terms in The Wheel of Time that consist of two words, such as “Aes Sedai” and “Lews Therin”, that I wanted to be sure to include in my topics. This didn’t drastically improve performance, but it did help slightly with interpretability.
The combination of these two techniques, in my opinion, worked astoundingly well. After playing around with the number of topics, I settled on twenty. Even with this large number of topics, the topics I found were each distinct. The topics I found generally fell into three categories. First, there were major characters such as Rand, Mat, and Perrin. Next there were recurring groups, such as the Aiel and Aes Sedai. Finally there were specific storylines, such as Emond’s field (the town where the main characters start), and the Last Battle. After finding the topics, I plotted their presence across all the chapters in the series, which you can see below.
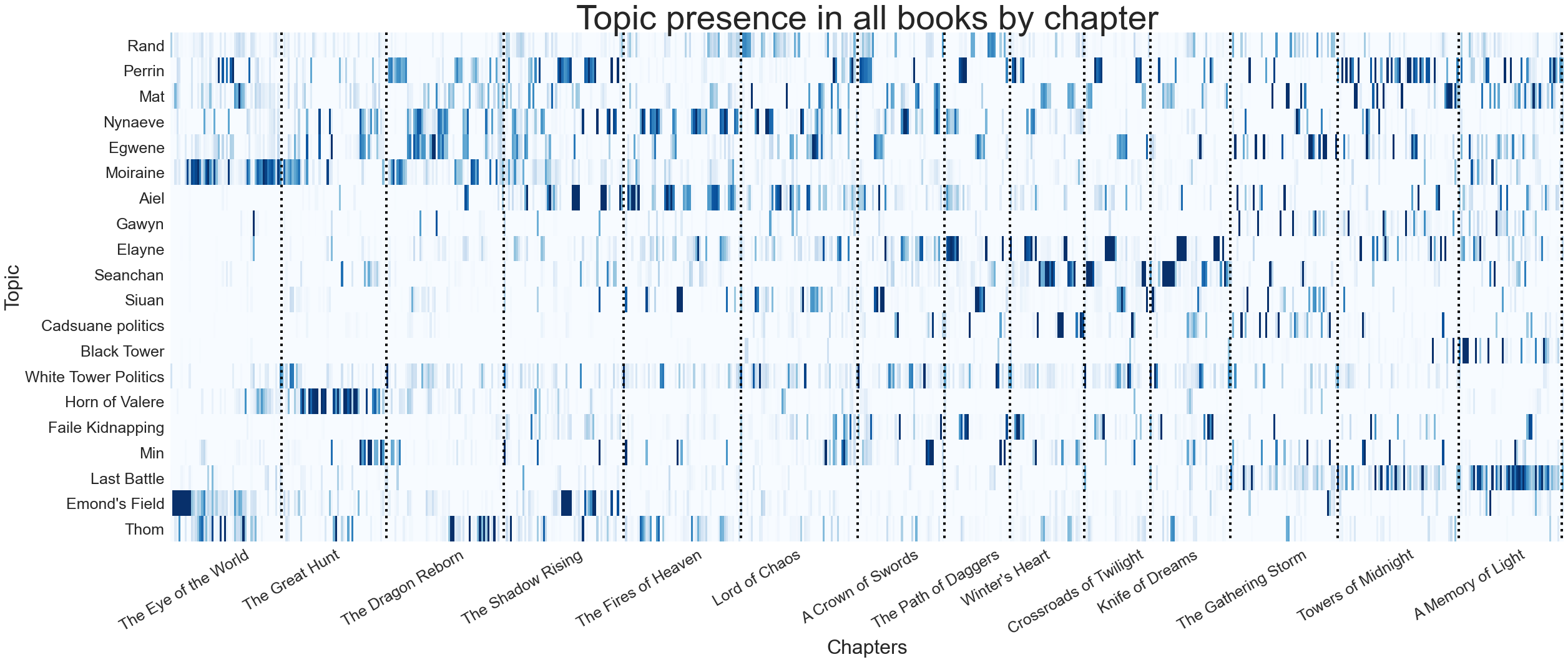
The NMF model does seem to accurately capture the presence of the topics with a high degree of accuracy. For example, it captures the first appearance of Elayne and Gawyn in the first book, and Perrin’s absence in the fifth book, Fire of Heaven. Interestingly, the three plotlines that the model made topics (Emond’s Field, Horn of Valere, and The Last Battle) are plotlines where many of the main characters are together in one place (something that is not true for many of the middle books), so perhaps the presence of these topics could be an indirect measure of character density. Overall, given the distinctness of the topics and the way that they correctly seem to evolve over the course of the story I am quite happy with how the topic modeling turned out.
Correlation of topics with ratings
Next, I wanted to investigate how the presence of certain topics correlate with the ratings of the books. Within the community, the least enjoyed books (books 8, 9, and 10) are collectively known as “The Slog” and are infamous for disliked plotlines such as the kidnapping of one of the main character’s love interest, Faile, and for the main plot not advaning a great deal. I wanted to see if we could see this if I could find the topics that people seem to enjoy the most and the least. Such an analysis could be useful for the writers of the upcoming show to have when deciding who/what to cut. The results of my analysis, which consisted of finding the pearson correlation coefficient between the presence of all topics in a chapter and the overall rating for the book that contains that chapter, is shown below.
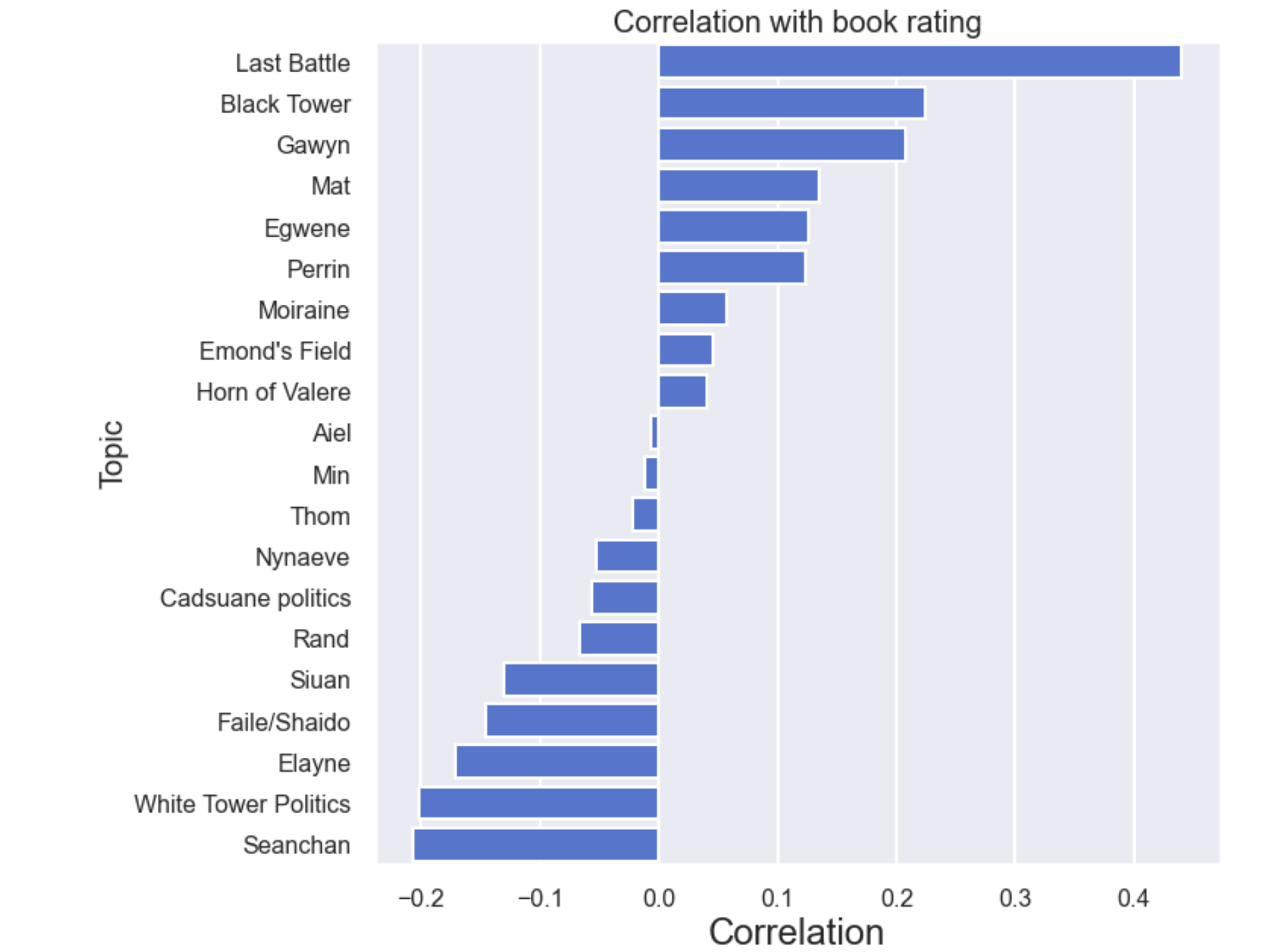
The results here are somewhat of a mixed bag. It certainly makes sense that the Last Battle has the highest positive correlation with book rating (this topic is localized in the last few books and those are extremely well regarded by fans) and the aforementioned Faile plot is at near the bottom. However, it doesn’t seem to make sense that Gawyn, who is a widely hated character, should be so close to the top. I think the issue here is that I only used book ratings, rather than chapter by chapter ratings (which I could not find), and that I did a simple correlation coefficient as opposed to a regression. The Gawyn chapters happen later in the series, so my guess would be that they would be regarded as the worst chapters in the best books, hence the high positive correlation with ratings.
Making character networks
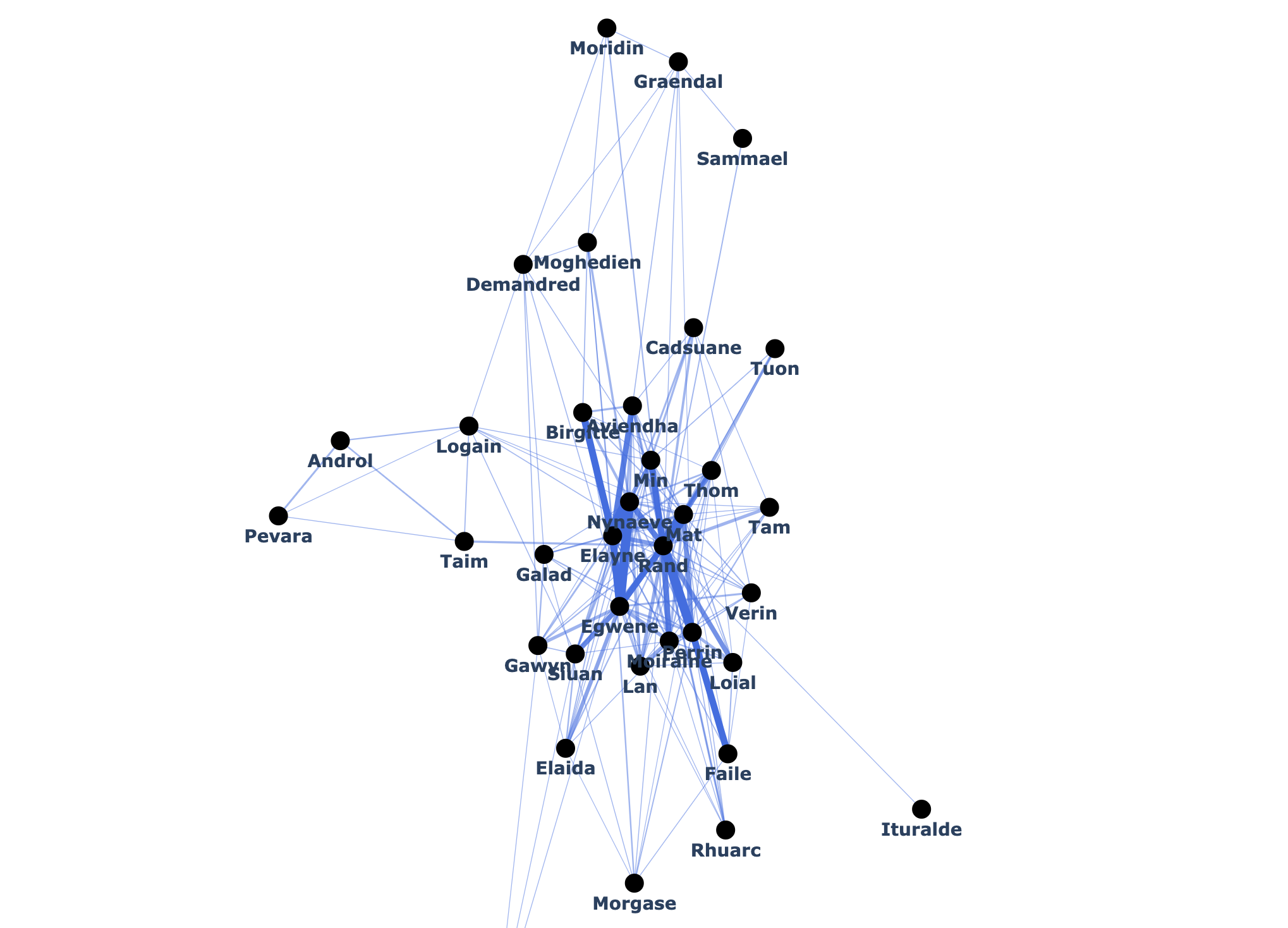
Somewhat as an aside from topic modeling, because there are so many characters I wanted to visualize character interactions throughout the books as a network (or more accurately, as an undirected graph). I went through the cleaned text and found all the instances where two characters’ names appeared within a certain number of words of each other. I found these connections individually for each chapter as well as cumulatively in the story at that chapter. I put all of these into a networkx network objects and plotted them using plotly, an example of which you can see below. I only used a subset of characters as otherwise the graph was simply too croweded. As a sidenote, the process of deciding where nodes of a graph is surprisingly deep, with the algorithm I decided to use treating nodes as experiencing a repulsive pseudogravity and the edges acting as attractive springs with strength determined by edge weight (i.e. the number of times two characters interacted). It’s interesting to see the patterns that emerge, even if they are to be expected. The main characters are in the center and are strongly connected to each other, while side characters that belong to distinct groups, such as the Forsaken (Moridin, Graendal, Sammael, Demandred, and Moghedien) or characters associated with the Black Tower (Androl, Pevara, Taim, and Logain) form subnetworks off to the side of the main cast.
Conclusion
I enjoyed doing this project a lot. The Wheel of Time is one of my favorite series of all time, so getting to use it as a dataset in a project was a lot of fun. It was interesting to see what insights I could gleam using NLP techniques and how those matched up to my expectations. If you want to see more detail into how I did things, you can check out the repo for this project here. I also made a streamlit app where you can explore the topics I found and the character networks, which you can run by downloading the repo. When I recieve my invitation to host that app on streamlit, I’ll update this post with the link to that so it’s more accessible if you’re curious!